Isolate CPU cores and run your algorithms on them.
It is possible to isolate individual cores from the scheduler available in linux, as it provides individual CPU specific sets for each core in the kernel.
This CPU set then allows developers to modify the scheduler's behavior. Before we go into the depths of this I would like to clear somethings here itself,
- First and foremost though this tutorial says you can completely isolate the core for running your own piece of code that might not be totally true as there are still some of the processing in the kernel that will require the execution time.
- Second the most important we will try to isolate the core from the kernel activities also so that we will get the most out of it.
As we all know or must know that bootloader passes the details of the underlying hardware to the linux kernel, hence we know the hardware description to some extent*.
The introduction of SMP was a great achievement, lets go ahead and discuss what may come in the way or so to say why the algorithms you run normally on your system may not yield accurate results or execute efficiently.
All the process in the linux by default run a policy of RR (SCHED_OTHER) time is divided equally among the processes. Hence if you run your algorithm/program, chances are that other processes may influence the results, specially if you have a time taking operations and calculations to perform. Hence we want to dedicate a whole core to just run a single program or application only.
To do this first we will isolate the cores for our own purpose by using the options which are provided by the linux during the boot-time and modify the parameters passed by the bootloader to the linux kernel, the details explanation of all these argument can easily be read in the kernel-parameters.txt in Documentation folder of a linux kernel source.
Below image shows underlined, some of the bootarg passed to linux, just add the
islocpu as defined below with the cores you want to separate separated by commas.
isolcpus=corenum
for example here to isloate CPU core write after a space
isolcpus=1,2,3...
Here "ro quiet splash" are some of the bootargs, add isolcpus="1,2" after splash for isolating 1 and 2 cores.
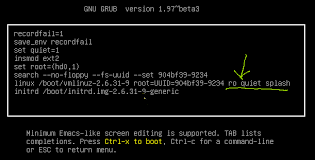
This allows the listed processor to be isolated from user-space scheduling.
Avoid isolating all the core, and check through proc to confirm that its in action. Also some special things need to be taken care of if your are using server that support NUMA.isolcpus=1,2,3...
Here "ro quiet splash" are some of the bootargs, add isolcpus="1,2" after splash for isolating 1 and 2 cores.

This allows the listed processor to be isolated from user-space scheduling.
You can check whether the bootargs were passed correctly through "cat /proc/cmdline" .
Also to see that it took some effect, run the top utility and you must have only kernel services and threads running on isolated core for example like kworker , ksoftirq, watchdog etc.
These are inherent to cores and are hard to isolate, for those from embedded domain can understand the importance of these task, failure to do so can lead to failure of machine as a whole.
So we have prevented our userspace processes to use our core, believe it or not that is a very big step as the 90% of disturbance occur due to preemption of the process when their epoch expire.
How to make it better?
This scenario can improved, considering we an prevent the flow of execution away from the code we intend to run.We
can achieve this by disabling the interrupts on that core which might not
be possible in userspace, but linux provides a feature of interrupt
affinity which gives a large possibility of landing interrupt on other
cores.
The proc filesystem does this job, you can see the list of all irq lines in the linux
in "/proc/irq/" these line may be shared but that doesn't matter.
The affinity of each line can be changed by writing into the "smp_affinity" in the same directory.
For more details on this feature see the following link using the smp through procfs.
In my case I want to use CPU0 for processing interrupts hence I give a bitmask of 1 (0001).You can do this on all interrupt lines, this will prevent any interrupt(apart from some) from disturbing the execution flow.
in "/proc/irq/" these line may be shared but that doesn't matter.
The affinity of each line can be changed by writing into the "smp_affinity" in the same directory.
For more details on this feature see the following link using the smp through procfs.
In my case I want to use CPU0 for processing interrupts hence I give a bitmask of 1 (0001).You can do this on all interrupt lines, this will prevent any interrupt(apart from some) from disturbing the execution flow.
Now that the core is isolated how do we use one?
The core isolated can be easily used by forking up a process, changing its scheduling parameters and by using CPU sets or you can just use the pthread library.
In general case we could avoid any system level code and solve problem easily using the taskset utilty and then changing its real time scheduling policy using the chrt utility to start an application and change its execution context. For both these options you must be root.
I have given a sample code that uses threading on the isolated core and performs selection sort on a dataset on an isolated CPU core and the time taken by it.
In general case we could avoid any system level code and solve problem easily using the taskset utilty and then changing its real time scheduling policy using the chrt utility to start an application and change its execution context. For both these options you must be root.
I have given a sample code that uses threading on the isolated core and performs selection sort on a dataset on an isolated CPU core and the time taken by it.
It consist of a main program which kick off one thread with different scheduling policy and with real-time priority,
Main Code.
#define _GNU_SOURCE #include<sched.h> #include<stdio.h> #include<stdlib.h> #include<time.h> #include<pthread.h> #include<unistd.h> #include"header.h" #include<string.h> #include<semaphore.h> #define SCHED_FIFO 1 #define CPU_VAL ((int)(*argv[1]-48)) extern void * selection(void *); extern void * insertion(void *); /* This is the main program which generates a random * set of data and passes them to the underlying * algorithms running, in our case its a single sorting * algorithm ( selection sort) , but we have multiple * core, can run same algorithm on multiple data sets * NOTE: Just be careful perform deep copy when using * same data set for them. */ pthread_attr_t attr; int main(int argc, char *argv[]){ int i,j,k; int n; int ret; /* Create threads for your algorithm */ printf("Process id %d\n",getpid()); struct arg argument; cpu_set_t cpuset2; CPU_ZERO(&cpuset2); CPU_SET(CPU_VAL,&cpuset2); if(!CPU_ISSET_S(CPU_VAL,sizeof(cpuset2),&cpuset2)){ perror("Error in the Attribute Init"); exit(1); } int total_cores=sysconf(_SC_NPROCESSORS_ONLN); if((int)(*argv[1]-'0') > total_cores){ printf("INVALID CORE VALUE\n"); exit(1); } pthread_t thread1; struct sched_param sched_parameter; sched_parameter.sched_priority=99; if(pthread_attr_init(&attr)!=0){ perror("Error in the Attribute Init"); exit(1); } if(pthread_attr_setinheritsched(&attr,PTHREAD_EXPLICIT_SCHED)!=0){ perror("Error setting the sched inheritance parameter"); exit(1); } if(pthread_attr_setschedpolicy(&attr,SCHED_FIFO)!=0){ perror(" Error setting the sched priority"); exit(1); } if(pthread_attr_setschedparam(&attr,&sched_parameter)!=0){ perror("Error setting the sched parameter"); exit(1); } if(pthread_attr_setaffinity_np(&attr,sizeof(cpuset2),&cpuset2)!=0){ perror("Set Affinity failed\n"); exit(0); } if(argc!=2){ printf("Please Enter Exactly Two arguments .1 Core number For Selection\n"); exit(1); } /* Generating a random array using * a rand() function without any * seed */ while(1){ n=rand()%10; int a[n]; printf("Array is "); for(i=0;i<n;i++){ a[i]=rand()%10; printf("%d ",a[i]); } /* The Selection Sort can be run on the same * or the different processor as long as they * RT priority are higher. The Kworker thread * will not or gain minimum excecution time. */ argument.size=n; argument.a=a; argument.core_num=(int)(*(char *)argv[1]-48); ret=pthread_create(&thread1,&attr,selection,(void *)&argument); if(ret!=0){ printf(" Error %d",ret); perror("failed in creating new thread\n"); exit(1); } ret=pthread_create(&thread1,&attr,selection,(void *)&argument); if(ret!=0){ printf(" Error %d",ret); perror("failed in creating new thread\n"); exit(1); } pthread_join(thread1,NULL); printf("\n"); } }
#define _GNU_SOURCE #include<sched.h> #include<stdio.h> #include<time.h> #include<unistd.h> #include<stdlib.h> #include<pthread.h> #include"header.h" #include<semaphore.h> extern void swap(int * , int , int); extern pthread_attr_t attr; int sched_type; clockid_t cid; struct timespec ts; void * selection(void * arg){ printf("thread ID%d", pthread_self()); int i,j,k,ret; struct arg * arguments=arg; if(pthread_getcpuclockid(pthread_self(),&cid)){ perror("Failed to get the clock cid"); exit(1); } if(pthread_attr_getschedpolicy(&attr,&sched_type)){ perror("Failed to get sched policy"); exit(1); } if(sched_type!=1){ printf("Failed to set the policy to SCHED_FIFO\n"); exit(1); } int small_num_pos; int compare=0; int current=-1; int flag=-1; if(clock_gettime(cid,&ts)==-1){ perror("Failed in gettime of the thread"); exit(1); } long nano_startsec=ts.tv_nsec; /* Selection sort procedure */ for(j=0;j<arguments->size;j++){ compare=arguments->a[j]; for(k=j+1;k<arguments->size;k++){ if(compare>arguments->a[k]){ small_num_pos=k; compare=arguments->a[k]; } } if(compare<arguments->a[j]){ swap(arguments->a,j,small_num_pos); } } if(clock_gettime(cid,&ts)==-1){ perror("Failed in gettime of the thread"); exit(1); } long nano_endsec=ts.tv_nsec; printf(" Nano Secs :%ld \n",(nano_endsec-nano_startsec)); printf("Sorted Array is "); for(i=0;i<arguments->size;i++){ printf(" %d ",arguments->a[i]); } return 0; }
Comments
Post a Comment